
미국 배당성장주에 투자한다면 배당수익률 뿐만 아니라 과거 배당성장률을 보며 배당금의 지속가능 여부를 확인해야한다. S&P500 전체 종목의 배당 데이터를 단 3분 컷으로 자동 수집하고, 순위까지 매기는 방법을 정리한다. 코딩을 모르는 비개발자도 구글 Colab에서 복사&붙여넣기만하면 누구나 따라 할 수 있는 방식이다.
배당수익률 배당성장률 높은 미국주식

미국 배당성장주를 고르려면 여러 웹사이트와 블로그, 유튜브를 돌아다니며 배당수익률과 배당성장률을 동시에 확인한다. 필자가 자주 애용하는 시킹알파 웹사이트는 현재 배당수익률과 1년~10년간 배당성장률이 정리되어 있긴 하다. 하지만 유료 구독자가 아닌 한, 종목 별로 일일이 조회한 뒤 엑셀로 내려받고, 다시 정리해야 하는 번거로움이 있다.
그러면 인공지능의 도움을 받는 건 어떨까? 필자는 AI에게 “배당수익률 배당성장률 높은 미국주식의 데이터 알려줘.”로 물어봤다. 그런데 생각보다 할루시네이션으로 틀린 답변을 내놓는 경우가 많았다. AI는 기본적으로 ‘확률 모델’이다. 질문에 대해 정답을 데이터베이스에서 그대로 꺼내오는 것이 아니라, 주어진 문맥에서 가장 가능성이 높아 보이는 답변을 생성한다. 문장은 그럴듯하게 이어지지만, 숫자나 최신 데이터는 틀릴 수 있다. AI는 검색 엔진처럼 쓰면 안된다.
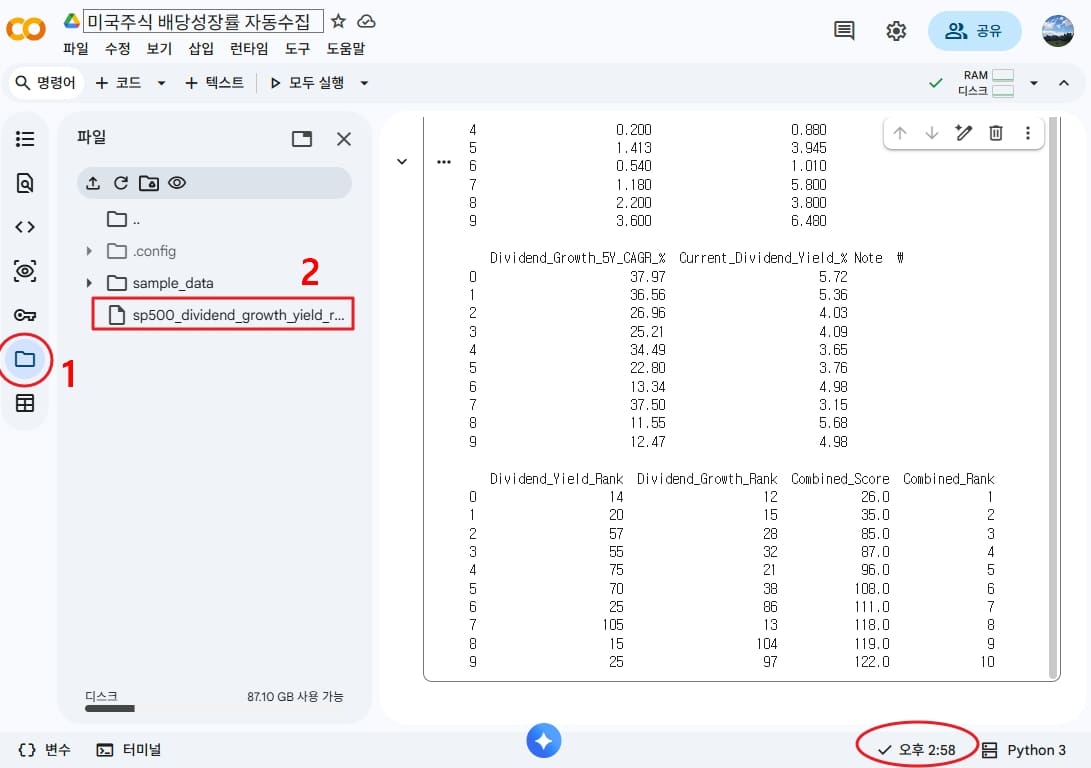
그래서 AI에게 배당수익률 배당성장률을 질문하는 방식이 아니라, S&P500 전체 종목의 배당수익률, 배당성장률 데이터를 수집하는 파이썬 코드를 짜 달라고 요청한 후 몇 번의 티키타카를 거친 후 → ‘야후 파이낸스 라이브러리1‘를 활용해 데이터를 수집하는 방법으로 바꿔봤다. 그리고 배당성장률, 배당수익률 높은 순위까지 매겨 랭킹까지 구해달라고 했다. 결과는 어땠을까? 정확도가 100% 였고, 정확히 2분 58초만에 500여 개가 넘는 S&P500 종목의 배당 데이터를 순식간에 정리했다. 결과물을 미리보자.
S&P500 티커 리스트를 가져와서, 특정일의 배당수익률(Dividend Yield)과 특정 기간의 배당성장률(Dividend Growth)를 뽑아내고 랭킹까지 3분컷으로 정리한다. 배당수익률 배당성장률 높은 미국주식의 순위는 엑셀 파일에서 확인 할 수 있고, 여러분도 직접 뽑을 수 있다. 배당수익률 배당성장률 높은 미국주식 상위권에 Ford(F), Invitation Homes(INVH), UPS(UPS), Target(TGT), Blackstone(BX), ARES Management(ARES) 말고는 모르는 회사들이 수두룩이다!
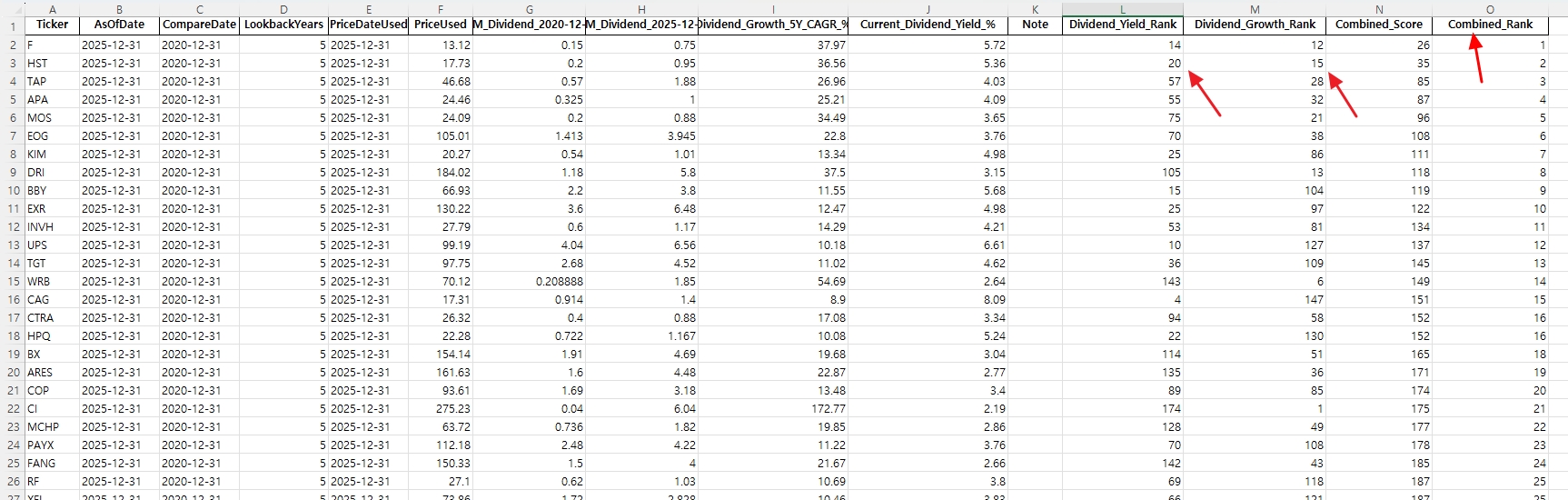
참고를 위해 S&P500 전체 티커, 회사명, 섹터를 정리한 파일도 첨부드린다.
자동 수집 방법
STEP 1. 구글 Colab 접속하기
https://colab.research.google.com
먼저 구글 Colab에 접속한다.+ 새 노트를 클릭한다.
구글 Colab은 브라우저에서 파이썬 코드를 실행할 수 있는 무료 노트북 환경이다. 별도로 파이썬을 설치하지 않아도 웹에서 코드를 실행할 수 있어 비개발자에게 특히 편리하다. Colab은 별도 설정 없이 사용할 수 있는 호스팅 Jupyter Notebook 서비스이며, 데이터 분석과 교육에 적합하다.(출처: Google)
STEP 2. 코드 붙여넣고 실행하기
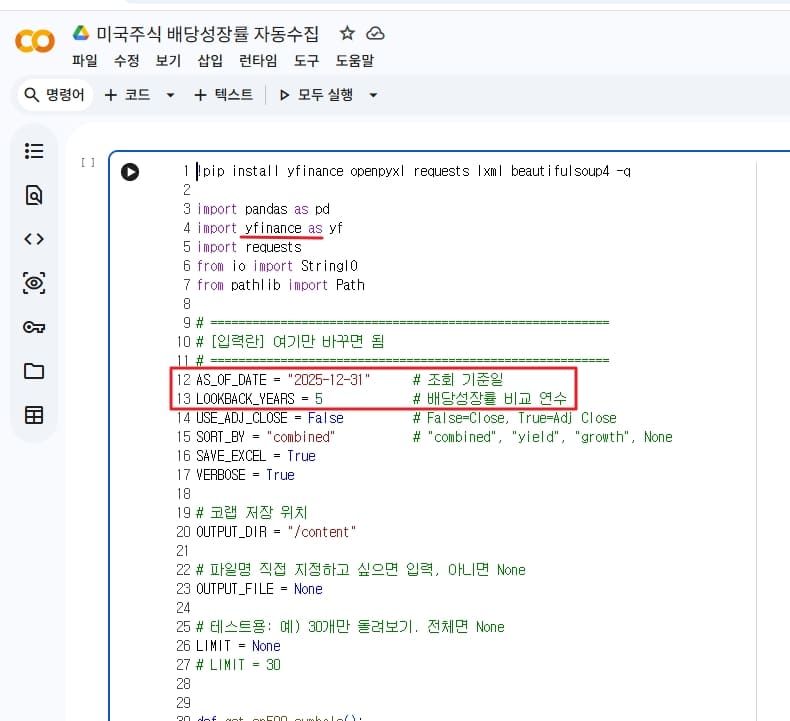
새 노트북이 열리면 위와 같이 코드를 입력할 수 있는 화면이 나온다. 만일 안 나오면 + 코드 버튼을 누른다. 아래 코드 스니펫(펼쳐보기)을 코드를 그대로 복사해서 붙여넣은 후, 검정색 화살표 버튼을 누르거나, Ctrl+Enter 단축키를 누르면 코드를 실행한다.
코드 스니펫 (펼쳐보기)
!pip install yfinance openpyxl requests lxml beautifulsoup4 -q
import pandas as pd
import yfinance as yf
import requests
from io import StringIO
from pathlib import Path
# =========================================================
# [입력란] 여기만 바꾸면 됨
# =========================================================
AS_OF_DATE = "2025-12-31" # 조회 기준일
LOOKBACK_YEARS = 5 # 배당성장률 비교 연수
USE_ADJ_CLOSE = False # False=Close, True=Adj Close
SORT_BY = "combined" # "combined", "yield", "growth", None
SAVE_EXCEL = True
VERBOSE = True
# 코랩 저장 위치
OUTPUT_DIR = "/content"
# 파일명 직접 지정하고 싶으면 입력, 아니면 None
OUTPUT_FILE = None
# 테스트용: 예) 30개만 돌려보기. 전체면 None
LIMIT = None
# LIMIT = 30
def get_sp500_symbols():
url = "https://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
df = pd.read_html(StringIO(response.text))[0]
symbols = df["Symbol"].tolist()
symbols = [symbol.replace(".", "-") for symbol in symbols]
return symbols
def get_last_available_price(series: pd.Series, target_date: str):
s = series.loc[:target_date].dropna()
if s.empty:
return None, None
return s.index[-1], float(s.iloc[-1])
def get_ttm_dividend(div_series: pd.Series, as_of_date: str):
end = pd.Timestamp(as_of_date)
start = end - pd.Timedelta(days=365)
s = div_series[(div_series.index > start) & (div_series.index <= end)].dropna()
return float(s.sum()) if not s.empty else 0.0
def calc_cagr(begin_value: float, end_value: float, years: float):
if begin_value is None or end_value is None:
return None
if begin_value <= 0 or end_value <= 0:
return None
return (end_value / begin_value) ** (1 / years) - 1
def add_ranking_columns(df: pd.DataFrame, lookback_years: int):
growth_col = f"Dividend_Growth_{lookback_years}Y_CAGR_%"
yield_col = "Current_Dividend_Yield_%"
result = df.copy()
result["Dividend_Yield_Rank"] = result[yield_col].rank(
ascending=False, method="min", na_option="bottom"
)
result["Dividend_Growth_Rank"] = result[growth_col].rank(
ascending=False, method="min", na_option="bottom"
)
result["Combined_Score"] = result[["Dividend_Yield_Rank", "Dividend_Growth_Rank"]].sum(axis=1)
result["Combined_Rank"] = result["Combined_Score"].rank(
ascending=True, method="min", na_option="bottom"
)
for col in ["Dividend_Yield_Rank", "Dividend_Growth_Rank", "Combined_Rank"]:
result[col] = result[col].astype("Int64")
return result
def run_sp500_dividend_screen(
as_of_date: str,
lookback_years: int = 5,
use_adj_close: bool = False,
save_excel: bool = True,
output_dir: str = "/content",
output_file: str = None,
sort_by: str = "combined",
verbose: bool = True,
limit: int = None
):
price_col = "Adj Close" if use_adj_close else "Close"
as_of_ts = pd.Timestamp(as_of_date)
compare_ts = as_of_ts - pd.DateOffset(years=lookback_years)
compare_date = compare_ts.strftime("%Y-%m-%d")
start_lookback = (compare_ts - pd.Timedelta(days=370)).strftime("%Y-%m-%d")
history_end = (as_of_ts + pd.Timedelta(days=2)).strftime("%Y-%m-%d")
if verbose:
print("=" * 60)
print(f"조회 기준일 : {as_of_date}")
print(f"비교 기준일 : {compare_date}")
print(f"배당성장률 기간 : {lookback_years}년")
print(f"주가 기준 컬럼 : {price_col}")
print(f"조회 시작일 : {start_lookback}")
print("=" * 60)
tickers = get_sp500_symbols()
if limit is not None:
tickers = tickers[:limit]
if verbose:
print(f"S&P500 대상 티커 수: {len(tickers)}")
results = []
for i, ticker in enumerate(tickers, start=1):
try:
tk = yf.Ticker(ticker)
hist = tk.history(
start=start_lookback,
end=history_end,
auto_adjust=False
)
dividends = tk.dividends.copy()
if not dividends.empty:
dividends.index = pd.to_datetime(dividends.index).tz_localize(None)
note_list = []
if hist.empty or price_col not in hist.columns:
asof_px_date, asof_px = None, None
note_list.append("주가 데이터 없음")
else:
price_series = hist[price_col].copy()
price_series.index = pd.to_datetime(price_series.index).tz_localize(None)
asof_px_date, asof_px = get_last_available_price(price_series, as_of_date)
if dividends.empty:
ttm_div_current = 0.0
ttm_div_past = 0.0
note_list.append("배당 데이터 없음")
else:
ttm_div_current = get_ttm_dividend(dividends, as_of_date)
ttm_div_past = get_ttm_dividend(dividends, compare_date)
if ttm_div_current == 0:
note_list.append(f"{as_of_date} 기준 최근 1년 배당금 없음")
if ttm_div_past == 0:
note_list.append(f"{compare_date} 기준 최근 1년 배당금 없음")
if asof_px is None or asof_px == 0:
dividend_yield = None
if "주가 데이터 없음" not in note_list:
note_list.append("기준일 주가 없음")
else:
dividend_yield = ttm_div_current / asof_px
div_growth_cagr = calc_cagr(
begin_value=ttm_div_past,
end_value=ttm_div_current,
years=lookback_years
)
results.append({
"Ticker": ticker,
"AsOfDate": as_of_date,
"CompareDate": compare_date,
"LookbackYears": lookback_years,
"PriceDateUsed": asof_px_date.strftime("%Y-%m-%d") if asof_px_date is not None else None,
"PriceUsed": round(asof_px, 4) if asof_px is not None else None,
f"TTM_Dividend_{compare_date}": round(ttm_div_past, 6),
f"TTM_Dividend_{as_of_date}": round(ttm_div_current, 6),
f"Dividend_Growth_{lookback_years}Y_CAGR_%": round(div_growth_cagr * 100, 2) if div_growth_cagr is not None else None,
"Current_Dividend_Yield_%": round(dividend_yield * 100, 2) if dividend_yield is not None else None,
"Note": "; ".join(note_list)
})
if verbose and (i % 25 == 0 or i == len(tickers)):
print(f"[진행] {i}/{len(tickers)} 완료")
except Exception as e:
results.append({
"Ticker": ticker,
"AsOfDate": as_of_date,
"CompareDate": compare_date,
"LookbackYears": lookback_years,
"PriceDateUsed": None,
"PriceUsed": None,
f"TTM_Dividend_{compare_date}": None,
f"TTM_Dividend_{as_of_date}": None,
f"Dividend_Growth_{lookback_years}Y_CAGR_%": None,
"Current_Dividend_Yield_%": None,
"Note": f"오류: {str(e)}"
})
if verbose:
print(f"[오류] {ticker} - {e}")
df = pd.DataFrame(results)
df = add_ranking_columns(df, lookback_years=lookback_years)
growth_col = f"Dividend_Growth_{lookback_years}Y_CAGR_%"
if sort_by == "combined":
df = df.sort_values(
by=["Combined_Rank", "Dividend_Growth_Rank", "Dividend_Yield_Rank"],
ascending=[True, True, True],
na_position="last"
).reset_index(drop=True)
elif sort_by == "yield":
df = df.sort_values(
by=["Dividend_Yield_Rank", growth_col],
ascending=[True, False],
na_position="last"
).reset_index(drop=True)
elif sort_by == "growth":
df = df.sort_values(
by=["Dividend_Growth_Rank", "Current_Dividend_Yield_%"],
ascending=[True, False],
na_position="last"
).reset_index(drop=True)
saved_path = None
if save_excel:
output_dir_path = Path(output_dir)
output_dir_path.mkdir(parents=True, exist_ok=True)
if output_file is None:
safe_asof = as_of_date.replace("-", "")
output_file = f"sp500_dividend_growth_yield_rank_asof_{safe_asof}_{lookback_years}y.xlsx"
saved_path = output_dir_path / output_file
df.to_excel(saved_path, index=False, engine="openpyxl")
print("\n엑셀 저장 완료")
print(f"파일명 : {saved_path.name}")
print(f"저장경로 : {saved_path}")
return df, saved_path
# =========================================================
# 실행
# =========================================================
df, saved_path = run_sp500_dividend_screen(
as_of_date=AS_OF_DATE,
lookback_years=LOOKBACK_YEARS,
use_adj_close=USE_ADJ_CLOSE,
save_excel=SAVE_EXCEL,
output_dir=OUTPUT_DIR,
output_file=OUTPUT_FILE,
sort_by=SORT_BY,
verbose=VERBOSE,
limit=LIMIT
)
print("\n상위 10개 미리보기")
print(df.head(10))
# =========================================================
# 코랩 자동 다운로드
# =========================================================
if saved_path is not None:
from google.colab import files
files.download(str(saved_path))STEP3. 엑셀 다운 받기
S&P 500 전 종목의 시가배당률, 배당 성장률 데이터를 수집하고, 랭킹을 매기기는 것도 포함해서 2분 58초 만에 엑셀파일로 추출했다. 파일 다운로드는 왼쪽 폴더 모양 패널을 클릭하고, 다운로드 받으면 된다. 끝.
코드 설명
평생 써먹을 수 있는 코드가 될 수 있도록, 날짜를 변경할 수 있도록 만들었다. AS_OF_DATE를 2026-04-27로 변경하면, 26년 4월 27일 주가 기준 배당수익률이 산출된다. 배당성장률도 원하는 기간에 따라 변경이 된다. LOOKBACK_YEARS를 1~10년 등 원하는 숫자를 넣으면 N년 후 배당성장률을 구할 수 있다.
S&P500 지수 종목은 편입출로 변경될 수 있기 때문에 Wikipedia 사이트의 S&P500 티커 리스트를 크롤링 수집하도록 했다.

배당성향, 재무 데이터(매출액성장률, 영업이익성장률, EPS성장률, RS, 현금흐름)를 수집하는 방법도 연구해봐야겠다.
바이브코딩으로 웹페이지까지 구현하는 것이 필자의 거대한 목표다. 😎
이 글도 같이 보면 더 좋아요!
- 야후파이낸스 라이브러리(yfinance library)는 Yahoo Finance에서 제공하는 주식 데이터에 접근할 수 있도록 열어둔 파이썬 패키지이다. 엑셀에서 함수를 쓰듯이, 파이썬에서는 라이브러리를 이용해 데이터를 자동으로 가져올 수 있다. ↩︎